It’s been a quite a while since I truly enjoyed programming at work. Don’t get me wrong. I like wrangling with code to make interesting stuff happen. The problem is that for a long time now, making interesting stuff happen with code hasn’t been the end game. Since the last ten years or so, it’s become incredibly more complex to get finished code to start working in the real world (aka production). Some say it’s because we OD’d on microservices. That probably true but there’s more to it than that alone.
Of Skyscrapers and Music
Back in the 1970s the popular opinion among software engineering experts was that software development is like building skyscrapers and bridges. You needed to know exactly what you want to build before you start writing punching code. That led to the (now vilified) waterfall model of software development.
I believe the waterfall model made sense at that time. The programming was done on bespoke machines that were constructed for corporate customers and were usually housed in the same building as the corporate offices. The customers were all co-located, so they could give immediate feedback if something was broken.
The challenge was that the cost of producing broken software was pretty high for the programmer. Here’s a quote from someone on Quora about programming on old hardware:
When I started to learn programming as a Physics student in the early 80s, I was sitting in front of a card typewriter and typed my [Fortran] program onto punched cards - one line per card with a maximum of 80 characters. To compile and run my program on a mainframe computer involved taking the stack of cards (never drop them or you will have to manually sort them!) to a card reader and “feed” them into the pre-processing unit.
The binary version of my program including some cards with some machine instructions was then put into a compile queue and once it was successfully compiled, it was placed into an execution queue. Based on one’s priority, it could take a few minutes or even half a day until your program was executed.
The output of this entire process was then printed onto “endless” paper tape and placed into an output bin for me to pick up. If I had a syntax or other error in my program, I would get a corresponding error message in my output and I had to start this process from the beginning after correcting the error.
Ouch.
Things were much better for people who were programming in the 80s through to mid/late 2000s. The computers became interactive, thanks to the attached CRT displays and keyboards. Hardware was a lot more standardised, thanks to the IBM PC. Even if it wasn’t, a lot of hardware peculiarities were abstracted by higher level programming languages like C. CPUs used to be single-core. They weren’t much too powerful but rapidly gaining strength, as was the available RAM. Floppies and hard disks started appearing for data storage. Also, the Internet was still in its infancy.
Programmers back then spent most of their time sussing out the most efficient algorithms that would fit in the minuscule quantities of RAM (remember the 640 kB meme?) and run fast enough on the measly compute power of the CPUs of that era.
This was also the age of shrink-wrapped software where there was a definite end point for software changes before it went to the Floppy/CD masters.
In a way, this was the best time to be a programmer. The development environment was way less painful and the production environment (customers) were far removed from them, with support tickets being the only channel on which they could be… bugged.
This was the time when software engineers decided that they were not construction workers but creative artistes like writers or music composers. They went on to invent concepts like agile development (which later got instutionalised beyond recognition) and eXtreme Programming.
Ah, these were the good old days that I can vouch for. Also, here’s an obligatory quote from Quora:
[Programming in the 80s and 90s] was much less chaotic than it is today. In those days, I programmed in FORTRAN and C using fairly simple toolchains.
Things haven’t been the same since. They’ve become worse, trust me.
Welcome to the Hospitality Business
By the start of 2010s, two massive developments changed the scene dramatically for the 90s’ creative programmers.
- Multi-core CPUs with Non-Uniform Memory Architecture
- The Internet as the dominant software delivery channel
See, back in the 90s and early 2000s, through all the major advancements undergoing mass consumption hardware, the conceptual computer architecture remained constant – single-threaded x86 CPUs, with single-tier memory model and block storage devices.
If you doubt the impact that this architecture had on programming, just look at the sheer number of apps for PC/Mac that just don’t scale with multi-core CPUs even to this day – more than 15 years on since the first dual-core Pentium was launched.
As for the Internet, well, it’s been a massive game-changer in software development. The bar for defensive programming has been raised multiple orders of magnitude – the simplistic 1980s’ memory abstraction as used in C/C++ is no longer even acceptable.
Even more significantly, the software distribution model has changed dramatically. The most effective software monetisation model now is SaaS – Software as a Service – where you don’t ship neatly packed versions of code for others to run on their computers. You run your own code on your own computers and you’re responsible for ensuring that it’s running flawlessly 24x7x365… x whatever the age of your company is.
Welcome to the hospitality business where your customer is a paying visitor to your premises that happen to be located in a dangerous neighbourhood.
The customer rarely gives you feedback and doesn’t like opening support tickets, but always does judge your service – the speed, the taste, the decor, the safety of your service. And if they don’t like your business they’d quietly walk away to the business next door that’s serving the same cuisine in the same price range but with different decor and cutlery.
State of the Art
One consequence of the programming-as-hospitality age is the rise of the “full cycle programmer”. The programmer doesn’t just write code and disconnect. The programmer needs to attend to how the program is running in production and address issues live. You can’t shut the restaurant down if a customer throws up between the tables. You isolate the fault and operate around it until it is remedied.
The full cycle programmer also needs to understand the context in which the program is executing. It’s not just the quirks of the immediate computer (server or container), it’s the entire topology of distributed services that the application is comprised of.
Add to this the need to modify the program while still maintaining “99.9[9…]% uptime” and things get rather out of hand really fast. Like mentioned in this quora quote:
We have Docker, Kubernetes, AWS, Azure, and a ton of other tools that we must navigate. We have dozens of new languages trying to pull us away from the tried-and-true, for example: Clojure, D, Dart, Elixir, Elm, F#, Go, Haskell, Julia, Kotlin, Lua, OCaml, Rust, Scala, TypeScript, etc.
And I’ve just barely scratched the surface! It’s all rather overwhelming.
Docker, Kubernetes, tons of other tools and the dozens of new languages are all attempts to cope with the increased demands on security, parallelism and continuous operation.
However, they’re not the solution. They’re merely stepping stones towards the solution, which begs the question “why do we have this complexity?”. The root cause is that we do not have a conceptual model for cloud computing and continuously evolving online services. Developing online software services without that model is like writing a modern desktop application with a programming language that pre-dates C. It’s just too complex.
That’s also the reason why I don’t enjoy programming as much now. I need to spend way too much effort in wiring together all the components of my distributed topology in a resilient, secure and scalable way. In some ways I can relate to that programmer who was punching Fortran programs onto cards – way too much effort spent on working the machine, as opposed to having the machine do your work.
Introducing the MetaComputer™
In 1992, the NCSA showcased a “Metacomputer”, which they defined as follows:
The Metacomputer is a network of heterogeneous, computational resources linked by software in such a way that they can be used as easily as a personal computer.
Nice.
This was their schematic for the Metacomputer:
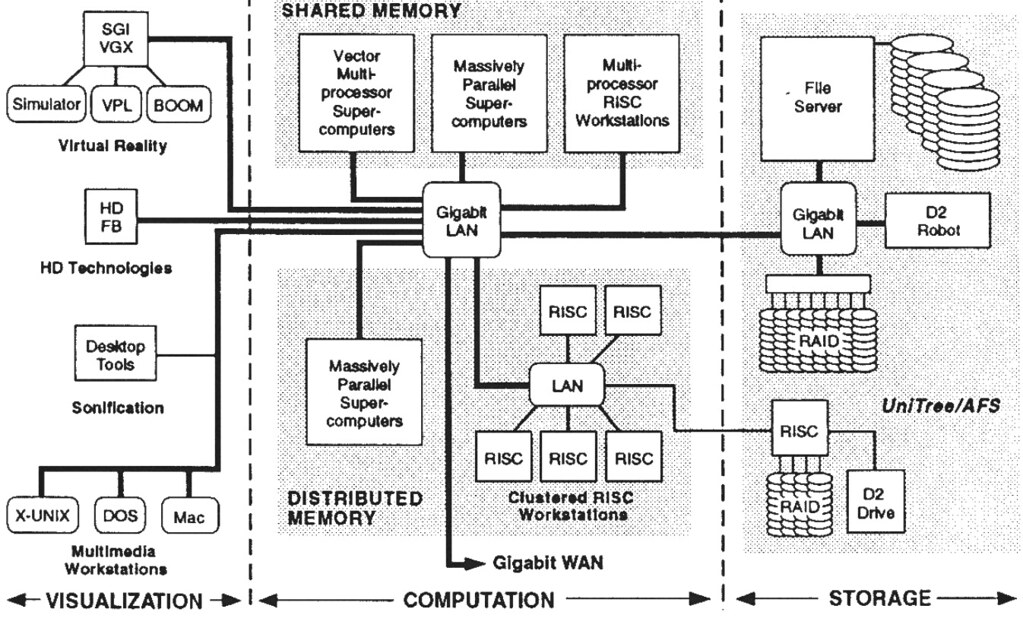
If you look at it carefully, it’s not that hard to extrapolate this schematic towards current cloud environments with neat sections for compute, storage and a web console to access all of these resources. Interestingly, the authors of the NCSA Metacomputer paper only talked at a surface level about the programming model.
One recent effort I know of that tries to offer a unified metacomputer presentation is Apache Mesos. Mesos aspires to be like Linux, except that it runs on a large cluster of machines and offers a unified view into them along with some resource management APIs.
Unfortunately, that’s not the kind of abstration a lot of people really need. The places where Mesos is most applicable is with large scale batch jobs or self-terminating tasks rather than always-on interactive services.
The other contender is the greek k-word. I mean kubernetes. Kubernetes promises to solve a lot of problems associated with programming for large scale distributed systems. Unfortunately, it was designed by gods of intellect with lots of PhDs and places a very high bar on the intellect of people eligible to write programs for it.
If you don’t believe me, there’s a Downfall (Hitler) parody for it. There’s also a meme about it:
Oh actually, there’s a Twitter account full of memes about kubernetes!.
To be fair, kubernetes is a great piece of engineering that solves many problems related to operating distributed applications in a reliable manner. However, for most developers, it’s too large scale low level. Recommending kubernetes as a computing model is like recommending LLVM when someone asks for a general purpose programming language. It’s not the right level of abstraction.
Anyway, the point is, the average billion-dollar tech company of today demands a lot from its programming staff and the programmers are still working with an out-dated computing model that were meant for single-threaded non-networked computers.
This is why we need a new computing model with new conceptual building blocks and new programming models to build applications with them. Not the IaC, or CDK – they’re great for automating infrastructure provisioning and access but that’s not really the concern of a programmer, even though it’s their responsibility.
So what is this computing model for, indeed? I’ll answer this question in The MetaComputer™ (Part “What” of 3) of this series, coming up next.
Meanwhile, I’d love to invite you to join the MetaComputer™ organisation on GitHub to discuss further. The logo of the organisation was generated by DALL·E-2, by the way.
PS: I didn’t include the evolution of front-ends (browsers, mobile apps) because there’s not a lot of disconnected apps (i.e. having no “backend”) so it’s inconsequential to the discussion here. I also didn’t include the evolution of data storage because SQL and the relational model have held strong as a conceptual model for the last five decades, despite some buzz about NoSQL.